注意
单击此处下载完整的示例代码
音频重采样¶
本教程介绍如何使用 torchaudio 的重采样 API。
import torch
import torchaudio
import torchaudio.functional as F
import torchaudio.transforms as T
print(torch.__version__)
print(torchaudio.__version__)
外:
1.12.0
0.12.0
制备¶
首先,我们导入模块并定义辅助函数。
注意
在 Google Colab 中运行本教程时,请安装所需的软件包 替换为以下内容。
!pip install librosa
import math
import time
import librosa
import matplotlib.pyplot as plt
import pandas as pd
from IPython.display import Audio, display
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
DEFAULT_OFFSET = 201
def _get_log_freq(sample_rate, max_sweep_rate, offset):
"""Get freqs evenly spaced out in log-scale, between [0, max_sweep_rate // 2]
offset is used to avoid negative infinity `log(offset + x)`.
"""
start, stop = math.log(offset), math.log(offset + max_sweep_rate // 2)
return torch.exp(torch.linspace(start, stop, sample_rate, dtype=torch.double)) - offset
def _get_inverse_log_freq(freq, sample_rate, offset):
"""Find the time where the given frequency is given by _get_log_freq"""
half = sample_rate // 2
return sample_rate * (math.log(1 + freq / offset) / math.log(1 + half / offset))
def _get_freq_ticks(sample_rate, offset, f_max):
# Given the original sample rate used for generating the sweep,
# find the x-axis value where the log-scale major frequency values fall in
time, freq = [], []
for exp in range(2, 5):
for v in range(1, 10):
f = v * 10**exp
if f < sample_rate // 2:
t = _get_inverse_log_freq(f, sample_rate, offset) / sample_rate
time.append(t)
freq.append(f)
t_max = _get_inverse_log_freq(f_max, sample_rate, offset) / sample_rate
time.append(t_max)
freq.append(f_max)
return time, freq
def get_sine_sweep(sample_rate, offset=DEFAULT_OFFSET):
max_sweep_rate = sample_rate
freq = _get_log_freq(sample_rate, max_sweep_rate, offset)
delta = 2 * math.pi * freq / sample_rate
cummulative = torch.cumsum(delta, dim=0)
signal = torch.sin(cummulative).unsqueeze(dim=0)
return signal
def plot_sweep(
waveform,
sample_rate,
title,
max_sweep_rate=48000,
offset=DEFAULT_OFFSET,
):
x_ticks = [100, 500, 1000, 5000, 10000, 20000, max_sweep_rate // 2]
y_ticks = [1000, 5000, 10000, 20000, sample_rate // 2]
time, freq = _get_freq_ticks(max_sweep_rate, offset, sample_rate // 2)
freq_x = [f if f in x_ticks and f <= max_sweep_rate // 2 else None for f in freq]
freq_y = [f for f in freq if f in y_ticks and 1000 <= f <= sample_rate // 2]
figure, axis = plt.subplots(1, 1)
_, _, _, cax = axis.specgram(waveform[0].numpy(), Fs=sample_rate)
plt.xticks(time, freq_x)
plt.yticks(freq_y, freq_y)
axis.set_xlabel("Original Signal Frequency (Hz, log scale)")
axis.set_ylabel("Waveform Frequency (Hz)")
axis.xaxis.grid(True, alpha=0.67)
axis.yaxis.grid(True, alpha=0.67)
figure.suptitle(f"{title} (sample rate: {sample_rate} Hz)")
plt.colorbar(cax)
plt.show(block=True)
重采样概述¶
要将音频波形从一个频率重新采样到另一个频率,你可以使用torchaudio.transforms.Resample()或torchaudio.functional.resample(). precomputes 并缓存用于重采样的内核,
while 会动态计算它,因此 using 将导致在重新采样时加速
使用相同参数的多个波形(参见 基准测试 部分)。transforms.Resamplefunctional.resampletorchaudio.transforms.Resample
两种重采样方法都使用带限 sinc 要计算的插值 信号值。实现涉及 卷积,因此我们可以利用 GPU / 多线程 性能改进。
注意
在多个子进程中使用重采样时,例如数据加载
使用多个工作进程,您的应用程序可能会创建更多
线程,您的系统无法有效处理。
在这种情况下,设置可能会有所帮助。torch.set_num_threads(1)
因为有限数量的样本只能代表有限数量的 频率、重新采样不会产生完美的结果,并且 of 参数可用于控制其质量和计算 速度。我们通过对数 正弦扫频,这是一个在 频率随时间的变化。
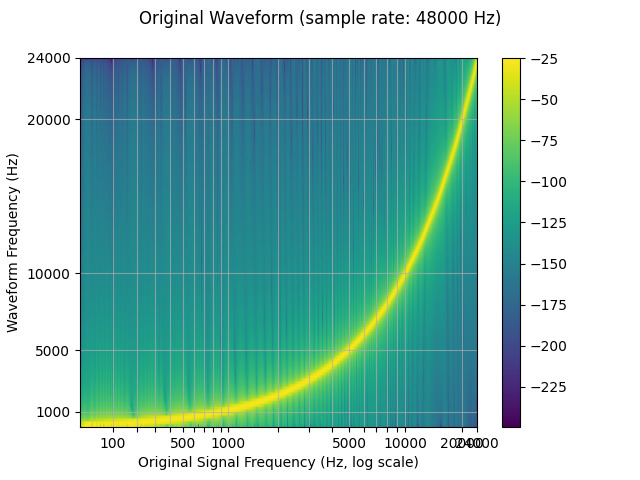
下面的频谱图显示了信号的频率表示, 其中 x 轴对应于原始 波形(对数刻度),y 轴频率 绘制波形,颜色强度为振幅。
sample_rate = 48000
waveform = get_sine_sweep(sample_rate)
plot_sweep(waveform, sample_rate, title="Original Waveform")
Audio(waveform.numpy()[0], rate=sample_rate)
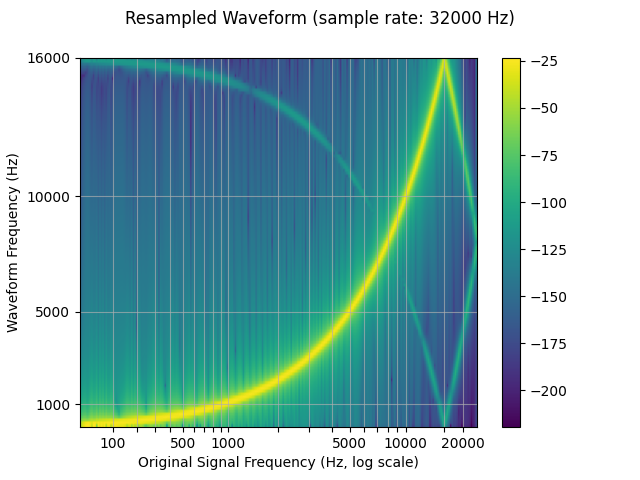
现在我们对其进行重新采样 (downsample)。
我们看到,在重采样波形的频谱图中,有一个 伪影,这在原始波形中不存在。
resample_rate = 32000
resampler = T.Resample(sample_rate, resample_rate, dtype=waveform.dtype)
resampled_waveform = resampler(waveform)
plot_sweep(resampled_waveform, resample_rate, title="Resampled Waveform")
Audio(resampled_waveform.numpy()[0], rate=resample_rate)
使用参数控制重采样质量¶
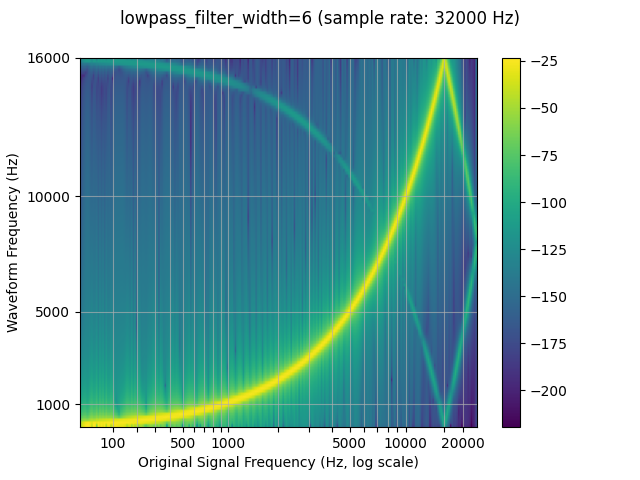
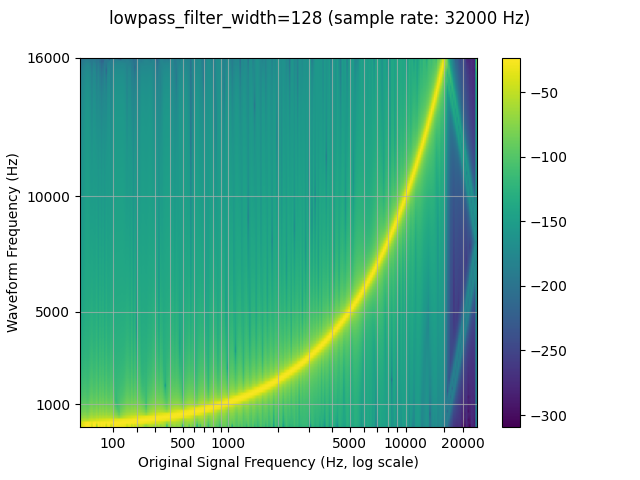
低通滤波器宽度¶
由于用于插值的滤波器无限延伸,因此该参数用于控制
用于对插值进行窗口化的 filter。它也被称为
自插值通过
在每个时间单位上为零。使用较大的滤波器更清晰、更精确,但计算量更大
贵。lowpass_filter_widthlowpass_filter_width
sample_rate = 48000
resample_rate = 32000
resampled_waveform = F.resample(waveform, sample_rate, resample_rate, lowpass_filter_width=6)
plot_sweep(resampled_waveform, resample_rate, title="lowpass_filter_width=6")
resampled_waveform = F.resample(waveform, sample_rate, resample_rate, lowpass_filter_width=128)
plot_sweep(resampled_waveform, resample_rate, title="lowpass_filter_width=128")
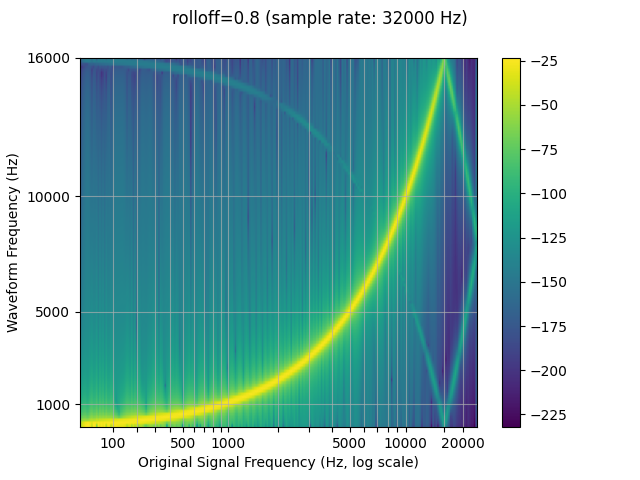
滚降¶
该参数表示为奈奎斯特频率的分数
frequency,即给定的
有限采样率。 确定低通滤波器截止和
控制混叠的程度,当频率
高于奈奎斯特频率的 Nyquist 频率被映射到较低的频率。下滚降
因此,将减少锯齿的数量,但它也会减少
一些更高的频率。rolloffrolloff
sample_rate = 48000
resample_rate = 32000
resampled_waveform = F.resample(waveform, sample_rate, resample_rate, rolloff=0.99)
plot_sweep(resampled_waveform, resample_rate, title="rolloff=0.99")
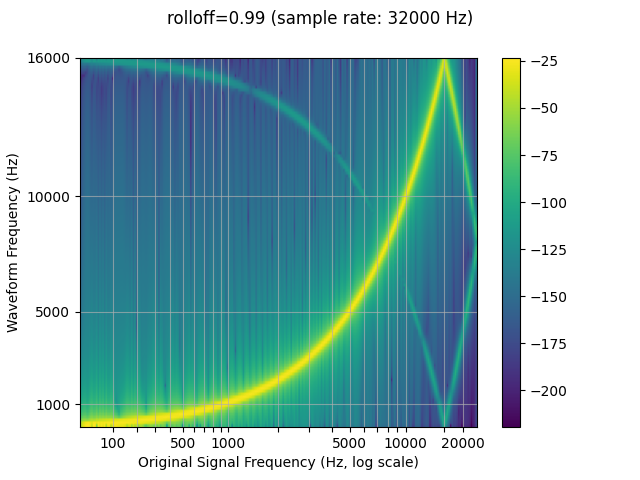
resampled_waveform = F.resample(waveform, sample_rate, resample_rate, rolloff=0.8)
plot_sweep(resampled_waveform, resample_rate, title="rolloff=0.8")
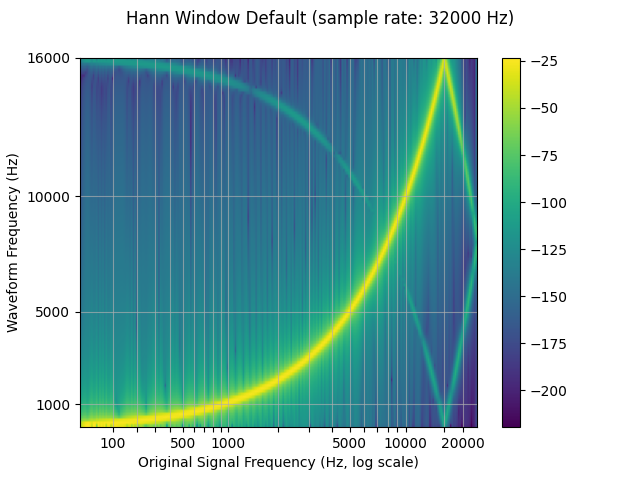
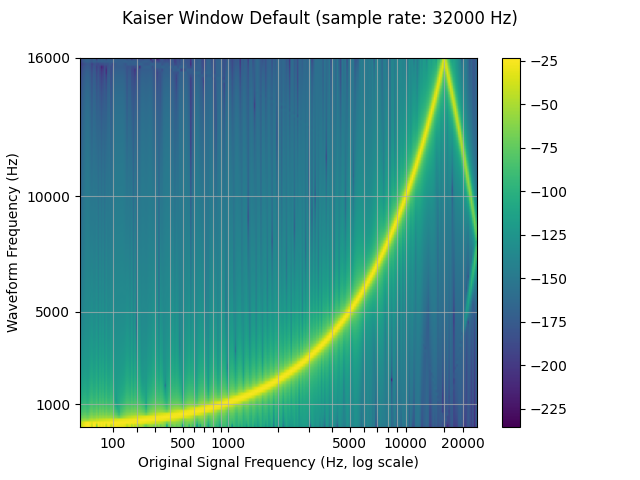
Window 函数¶
默认情况下,的 resample 使用 Hann 窗口过滤器,即
加权余弦函数。它还支持 Kaiser 窗口、
,这是一个近乎最优的窗口函数,它包含一个额外的参数,该参数允许设计
filter 和 impulse 的宽度。这可以使用 parameter 进行控制。torchaudiobetaresampling_method
sample_rate = 48000
resample_rate = 32000
resampled_waveform = F.resample(waveform, sample_rate, resample_rate, resampling_method="sinc_interpolation")
plot_sweep(resampled_waveform, resample_rate, title="Hann Window Default")
resampled_waveform = F.resample(waveform, sample_rate, resample_rate, resampling_method="kaiser_window")
plot_sweep(resampled_waveform, resample_rate, title="Kaiser Window Default")
与 librosa 的比较¶
torchaudio的 resample 函数可用于生成类似于
Librosa (Resampy) 的 Kaiser 窗口重新采样,有一些噪声
sample_rate = 48000
resample_rate = 32000
kaiser_best¶
resampled_waveform = F.resample(
waveform,
sample_rate,
resample_rate,
lowpass_filter_width=64,
rolloff=0.9475937167399596,
resampling_method="kaiser_window",
beta=14.769656459379492,
)
plot_sweep(resampled_waveform, resample_rate, title="Kaiser Window Best (torchaudio)")
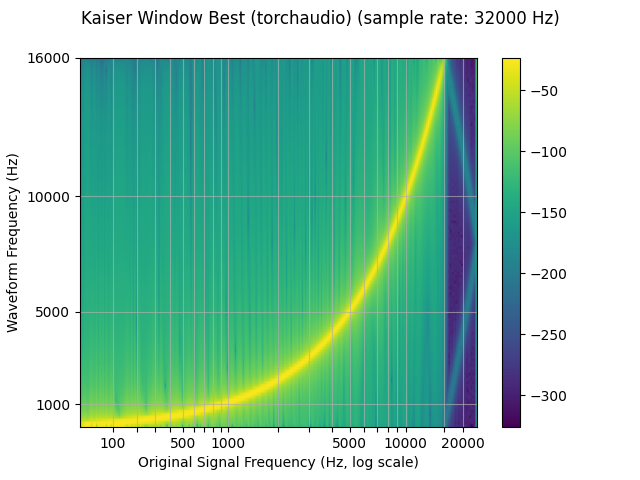
librosa_resampled_waveform = torch.from_numpy(
librosa.resample(waveform.squeeze().numpy(), orig_sr=sample_rate, target_sr=resample_rate, res_type="kaiser_best")
).unsqueeze(0)
plot_sweep(librosa_resampled_waveform, resample_rate, title="Kaiser Window Best (librosa)")
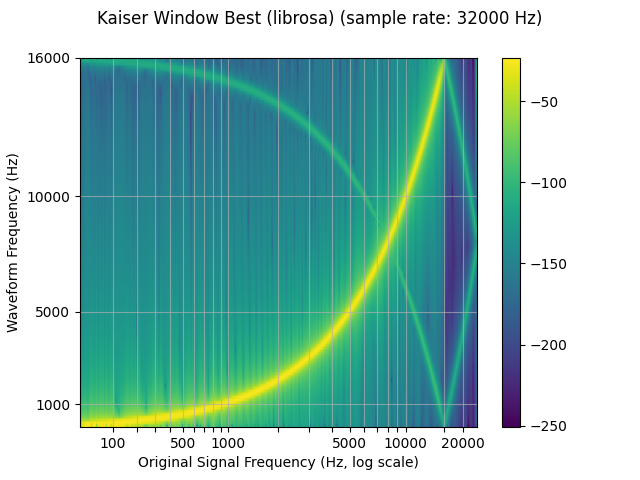
mse = torch.square(resampled_waveform - librosa_resampled_waveform).mean().item()
print("torchaudio and librosa kaiser best MSE:", mse)
外:
torchaudio and librosa kaiser best MSE: 2.08069011536601e-06
kaiser_fast¶
resampled_waveform = F.resample(
waveform,
sample_rate,
resample_rate,
lowpass_filter_width=16,
rolloff=0.85,
resampling_method="kaiser_window",
beta=8.555504641634386,
)
plot_sweep(resampled_waveform, resample_rate, title="Kaiser Window Fast (torchaudio)")
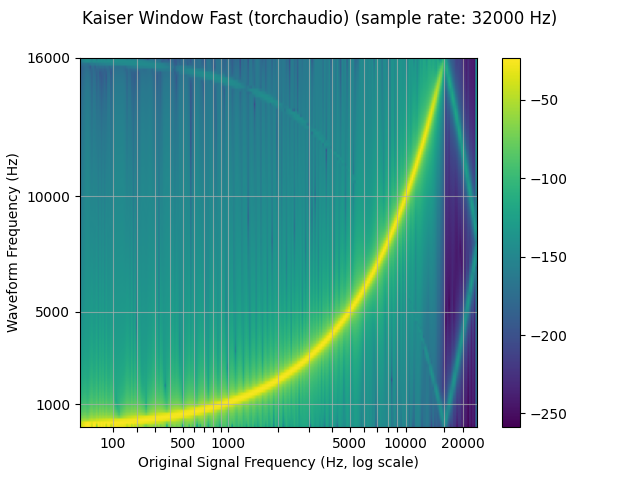
librosa_resampled_waveform = torch.from_numpy(
librosa.resample(waveform.squeeze().numpy(), orig_sr=sample_rate, target_sr=resample_rate, res_type="kaiser_fast")
).unsqueeze(0)
plot_sweep(librosa_resampled_waveform, resample_rate, title="Kaiser Window Fast (librosa)")
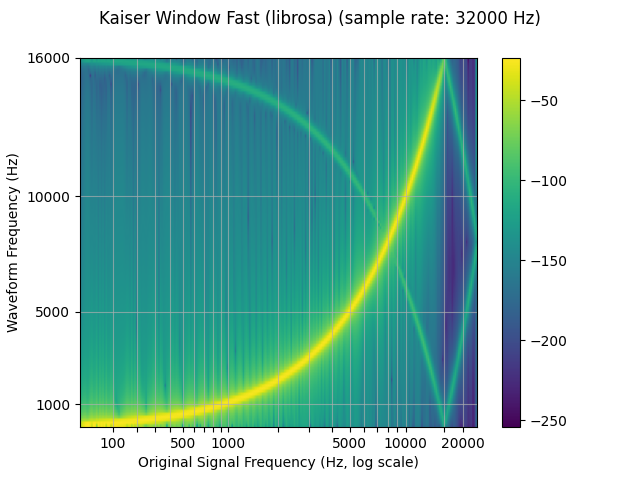
mse = torch.square(resampled_waveform - librosa_resampled_waveform).mean().item()
print("torchaudio and librosa kaiser fast MSE:", mse)
外:
torchaudio and librosa kaiser fast MSE: 2.5200744248600685e-05
性能基准测试¶
以下是
两对采样率。我们展示了性能影响
、窗口类型和采样率可以
有。此外,我们还提供了与 的比较,并使用它们的相应参数
在。lowpass_filter_wdithlibrosakaiser_bestkaiser_fasttorchaudio
详细说明结果:
较大的结果会产生较大的重采样核, 因此增加了内核计算的计算时间 和卷积
lowpass_filter_widthusing 会导致计算时间比 default 长,因为计算中间 窗口值 - 将导致采样率和重新采样率之间的 GCD 较大 在允许更小的内核和更快的内核计算的简化中。
kaiser_windowsinc_interpolation
def benchmark_resample(
method,
waveform,
sample_rate,
resample_rate,
lowpass_filter_width=6,
rolloff=0.99,
resampling_method="sinc_interpolation",
beta=None,
librosa_type=None,
iters=5,
):
if method == "functional":
begin = time.monotonic()
for _ in range(iters):
F.resample(
waveform,
sample_rate,
resample_rate,
lowpass_filter_width=lowpass_filter_width,
rolloff=rolloff,
resampling_method=resampling_method,
)
elapsed = time.monotonic() - begin
return elapsed / iters
elif method == "transforms":
resampler = T.Resample(
sample_rate,
resample_rate,
lowpass_filter_width=lowpass_filter_width,
rolloff=rolloff,
resampling_method=resampling_method,
dtype=waveform.dtype,
)
begin = time.monotonic()
for _ in range(iters):
resampler(waveform)
elapsed = time.monotonic() - begin
return elapsed / iters
elif method == "librosa":
waveform_np = waveform.squeeze().numpy()
begin = time.monotonic()
for _ in range(iters):
librosa.resample(waveform_np, orig_sr=sample_rate, target_sr=resample_rate, res_type=librosa_type)
elapsed = time.monotonic() - begin
return elapsed / iters
configs = {
"downsample (48 -> 44.1 kHz)": [48000, 44100],
"downsample (16 -> 8 kHz)": [16000, 8000],
"upsample (44.1 -> 48 kHz)": [44100, 48000],
"upsample (8 -> 16 kHz)": [8000, 16000],
}
for label in configs:
times, rows = [], []
sample_rate = configs[label][0]
resample_rate = configs[label][1]
waveform = get_sine_sweep(sample_rate)
# sinc 64 zero-crossings
f_time = benchmark_resample("functional", waveform, sample_rate, resample_rate, lowpass_filter_width=64)
t_time = benchmark_resample("transforms", waveform, sample_rate, resample_rate, lowpass_filter_width=64)
times.append([None, 1000 * f_time, 1000 * t_time])
rows.append("sinc (width 64)")
# sinc 6 zero-crossings
f_time = benchmark_resample("functional", waveform, sample_rate, resample_rate, lowpass_filter_width=16)
t_time = benchmark_resample("transforms", waveform, sample_rate, resample_rate, lowpass_filter_width=16)
times.append([None, 1000 * f_time, 1000 * t_time])
rows.append("sinc (width 16)")
# kaiser best
lib_time = benchmark_resample("librosa", waveform, sample_rate, resample_rate, librosa_type="kaiser_best")
f_time = benchmark_resample(
"functional",
waveform,
sample_rate,
resample_rate,
lowpass_filter_width=64,
rolloff=0.9475937167399596,
resampling_method="kaiser_window",
beta=14.769656459379492,
)
t_time = benchmark_resample(
"transforms",
waveform,
sample_rate,
resample_rate,
lowpass_filter_width=64,
rolloff=0.9475937167399596,
resampling_method="kaiser_window",
beta=14.769656459379492,
)
times.append([1000 * lib_time, 1000 * f_time, 1000 * t_time])
rows.append("kaiser_best")
# kaiser fast
lib_time = benchmark_resample("librosa", waveform, sample_rate, resample_rate, librosa_type="kaiser_fast")
f_time = benchmark_resample(
"functional",
waveform,
sample_rate,
resample_rate,
lowpass_filter_width=16,
rolloff=0.85,
resampling_method="kaiser_window",
beta=8.555504641634386,
)
t_time = benchmark_resample(
"transforms",
waveform,
sample_rate,
resample_rate,
lowpass_filter_width=16,
rolloff=0.85,
resampling_method="kaiser_window",
beta=8.555504641634386,
)
times.append([1000 * lib_time, 1000 * f_time, 1000 * t_time])
rows.append("kaiser_fast")
df = pd.DataFrame(times, columns=["librosa", "functional", "transforms"], index=rows)
df.columns = pd.MultiIndex.from_product([[f"{label} time (ms)"], df.columns])
print(f"torchaudio: {torchaudio.__version__}")
print(f"librosa: {librosa.__version__}")
display(df.round(2))
外:
torchaudio: 0.12.0
librosa: 0.9.1
downsample (48 -> 44.1 kHz) time (ms)
librosa functional transforms
sinc (width 64) NaN 15.23 0.44
sinc (width 16) NaN 24.25 0.40
kaiser_best 34.52 27.59 0.42
kaiser_fast 17.58 21.90 0.38
torchaudio: 0.12.0
librosa: 0.9.1
downsample (16 -> 8 kHz) time (ms)
librosa functional transforms
sinc (width 64) NaN 1.21 0.73
sinc (width 16) NaN 0.59 0.34
kaiser_best 12.36 2.03 0.82
kaiser_fast 4.39 0.73 0.36
torchaudio: 0.12.0
librosa: 0.9.1
upsample (44.1 -> 48 kHz) time (ms)
librosa functional transforms
sinc (width 64) NaN 32.91 0.44
sinc (width 16) NaN 35.77 0.37
kaiser_best 35.07 29.64 0.46
kaiser_fast 12.37 22.09 0.40
torchaudio: 0.12.0
librosa: 0.9.1
upsample (8 -> 16 kHz) time (ms)
librosa functional transforms
sinc (width 64) NaN 0.78 0.35
sinc (width 16) NaN 0.50 0.19
kaiser_best 12.69 0.90 0.39
kaiser_fast 5.28 0.66 0.22
脚本总运行时间:(0 分 5.492 秒)