在Xtensa HiFi4 DSP上构建和运行ExecuTorch¶
在这个教程中,我们将引导你完成设置流程,以在 Xtensa HiFi4 DSP 上构建 ExecuTorch,并在该平台上运行一个简单的模型。
Cadence 是一家软硬件供应商,提供多种计算工作负载的解决方案,包括在功耗受限的嵌入式设备上运行。 Xtensa HiFi4 DSP 是一种数字信号处理器(DSP),专为运行基于音频的神经网络而优化,例如唤醒词检测、自动语音识别(ASR)等。
除了芯片之外,HiFi4神经网络库(nnlib)还提供了一组优化的常用库函数,这些函数常用于NN处理,我们在本示例中使用它们来演示如何加速常见的操作。
除了能够在Xtensa HiFi4 DSP上运行之外,本教程的另一个目标是展示ExecuTorch的可移植性及其在低功耗嵌入式设备(如Xtensa HiFi4 DSP)上运行的能力。此工作流程不需要任何委托,它使用自定义操作符和编译器通道来增强模型,使其更适合在Xtensa HiFi4 DSP上运行。使用自定义量化器将激活和权重表示为uint8而不是float,并调用适当的运算符。最后,使用经过Xtensa内部函数优化的自定义内核提供运行时加速。
在这个教程中,你将学习如何导出一个针对Xtensa HiFi4 DSP的线性操作量化模型。
你还将学习如何编译和部署 ExecuTorch 运行时,使用在上一步骤中生成的量化模型所需的内核,在 Xtensa HiFi4 DSP 上运行。
注意
本教程中的 Linux 部分是在 Ubuntu 22.04 LTS 上设计和测试的,需要 glibc 2.34。其他发行版有可用的解决方法,但本教程不会涵盖这些内容。
前提条件(硬件和软件)¶
为了能够在Xtensa HiFi4 DSP上成功构建和运行ExecuTorch,您需要以下硬件和软件组件。
软件¶
x86-64 Linux 系统(用于编译 DSP 二进制文件)
-
此IDE支持多个平台,包括MacOS。您可以使用它在任何支持的平台上运行,因为您只会使用它来将后续教程中构建的DSP镜像烧录到板子上。
-
需要将固件镜像烧录到开发板上。您可以将此安装在与安装MCUXpresso IDE相同的平台上。
注意:根据 NXP 开发板的版本,可能会安装除 JLink 以外的其他调试器。无论如何,烧录操作都是通过 MCUXpresso IDE 以类似的方式进行的。
-
将此 SDK 下载到你的 Linux 机器上,解压它,并记下你存储它的路径。之后你将会需要这个路径。
-
下载到你的 Linux 机器上。这是构建 HiFi4 DSP 的 ExecuTorch 所需要的。
对于有优化内核的情况,请参阅 nnlib 仓库。
设置开发环境¶
步骤 1. 为了能够成功安装上述所有软件组件,用户需要通过下面链接的 NXP 教程进行操作。尽管该教程本身演示的是 Windows 环境的设置,但其中的大部分步骤也适用于 Linux 安装。
注意
在继续下一节之前,用户应该能够成功从上述教程中烧录 dsp_mu_polling_cm33 示例应用程序,并在UART控制台注意到指示Cortex-M33和HiFi4 DSP正在互相通信的输出。
步骤 2. 确保您已完成本页面顶部链接的 ExecuTorch 设置教程。
工作树描述¶
工作树是:
executorch
├── backends
│ └── cadence
│ ├── aot
│ ├── ops_registration
│ ├── tests
│ ├── utils
│ ├── hifi
│ │ ├── kernels
│ │ ├── operators
│ │ └── third-party
│ │ └── hifi4-nnlib
│ └── [other cadence DSP families]
│ ├── kernels
│ ├── operators
│ └── third-party
│ └── [any required lib]
└── examples
└── cadence
├── models
└── operators
提前编译(AoT)组件:
AOT文件夹包含所有用于将模型导出为ExecuTorch .pte文件的Python脚本和函数。在我们的案例中,export_example.py是一个API,它接受一个模型(nn.Module)和代表性的输入,并通过量化器(来自quantizer.py)运行。然后,一些编译器传递,也在quantizer.py中定义,会将运算符替换为芯片上受支持且优化的自定义运算符。任何需要计算的运算符都应在ops_registrations.py中定义,并在其他文件夹中有相应的实现。
操作符:
operators 文件夹包含两种类型的运算符:来自 ExecuTorch 可移植库的现有运算符和定义自定义计算的新运算符。前者只是将运算符分派到相关的 ExecuTorch 实现,而后者充当接口,设置自定义内核计算输出所需的一切。
内核:
kernels 文件夹包含在 HiFi4 芯片上运行的优化内核。它们使用 Xtensa 内在函数,在低功耗下提供高性能。
构建¶
在此步骤中,您将从不同的模型生成ExecuTorch程序。然后您将在运行时构建步骤中使用此程序(.pte 文件)将此程序烘焙到DSP镜像中。
简单模型:
第一个简单的模型旨在测试本教程的所有组件是否正常工作,仅执行加法操作。生成的文件名为 add.pte。
cd executorch
python3 -m examples.portable.scripts.export --model_name="add"
量化操作符:
另一种更为复杂的模型是自定义操作符,包括:
在两种情况下生成的文件都称为 CadenceDemoModel.pte。
cd executorch
python3 -m examples.cadence.operators.quantized_<linear,conv1d>_op
小型模型:RNNT 预测器:
The torchaudio RNNT-emformer 模型是一个自动语音识别(ASR)模型,由三个不同的子模型组成:编码器、预测器和连接器。 预测器 是一系列基础操作(嵌入、ReLU、线性、层归一化)的序列,可以通过以下方式导出:
cd executorch
python3 -m examples.cadence.models.rnnt_predictor
生成的文件名为 CadenceDemoModel.pte。
运行时¶
构建DSP固件镜像 在此步骤中,您将构建包含示例ExecuTorch运行器以及上一步骤生成的程序的DSP固件镜像。将此镜像加载到DSP上时,将会运行该程序所包含的模型。
步骤 1. 配置所需的环境变量,以指向您在上一步骤中安装的 Xtensa 工具链。需要设置的三个环境变量包括:
# Directory in which the Xtensa toolchain was installed
export XTENSA_TOOLCHAIN=/home/user_name/cadence/XtDevTools/install/tools
# The version of the toolchain that was installed. This is essentially the name of the directory
# that is present in the XTENSA_TOOLCHAIN directory from above.
export TOOLCHAIN_VER=RI-2021.8-linux
# The Xtensa core that you're targeting.
export XTENSA_CORE=nxp_rt600_RI2021_8_newlib
步骤 2. 克隆 nnlib 仓库, 其中包含了针对 HiFi4 DSPs 的优化内核和原语,使用 git clone git@github.com:foss-xtensa/nnlib-hifi4.git。
步骤 3。运行 CMake 构建。 为了运行 CMake 构建,你需要以下路径:
上一步生成的程序
NXP SDK 根目录的路径。这应该已经在 设置开发环境 部分安装好了。这个目录包含诸如 boards、components、devices 等文件夹。
cd executorch
./install_requirements.sh --clean
mkdir cmake-out
# prebuild and install executorch library
cmake -DCMAKE_TOOLCHAIN_FILE=<path_to_executorch>/backends/cadence/cadence.cmake \
-DCMAKE_INSTALL_PREFIX=cmake-out \
-DCMAKE_BUILD_TYPE=Debug \
-DPYTHON_EXECUTABLE=python3 \
-DEXECUTORCH_BUILD_EXTENSION_RUNNER_UTIL=ON \
-DEXECUTORCH_BUILD_HOST_TARGETS=ON \
-DEXECUTORCH_BUILD_EXECUTOR_RUNNER=OFF \
-DEXECUTORCH_BUILD_PTHREADPOOL=OFF \
-DEXECUTORCH_BUILD_CPUINFO=OFF \
-DEXECUTORCH_BUILD_FLATC=OFF \
-DFLATC_EXECUTABLE="$(which flatc)" \
-Bcmake-out .
cmake --build cmake-out -j<num_cores> --target install --config Debug
# build cadence runner
cmake -DCMAKE_BUILD_TYPE=Debug \
-DCMAKE_TOOLCHAIN_FILE=<path_to_executorch>/examples/backends/cadence.cmake \
-DCMAKE_PREFIX_PATH=<path_to_executorch>/cmake-out \
-DMODEL_PATH=<path_to_program_file_generated_in_previous_step> \
-DNXP_SDK_ROOT_DIR=<path_to_nxp_sdk_root> -DEXECUTORCH_BUILD_FLATC=0 \
-DFLATC_EXECUTABLE="$(which flatc)" \
-DNN_LIB_BASE_DIR=<path_to_nnlib_cloned_in_step_2> \
-Bcmake-out/examples/cadence \
examples/cadence
cmake --build cmake-out/examples/cadence -j8 -t cadence_executorch_example
在成功运行了上述步骤之后,你应该在其 CMake 输出目录中看到两个二进制文件。
> ls cmake-xt/*.bin
cmake-xt/dsp_data_release.bin cmake-xt/dsp_text_release.bin
在设备上部署和运行¶
步骤 1. 现在,您将从上一步生成的DSP二进制图像复制到在设置开发环境部分中创建的NXP工作区。将DSP图像复制到下图中突出显示的dsp_binary部分。
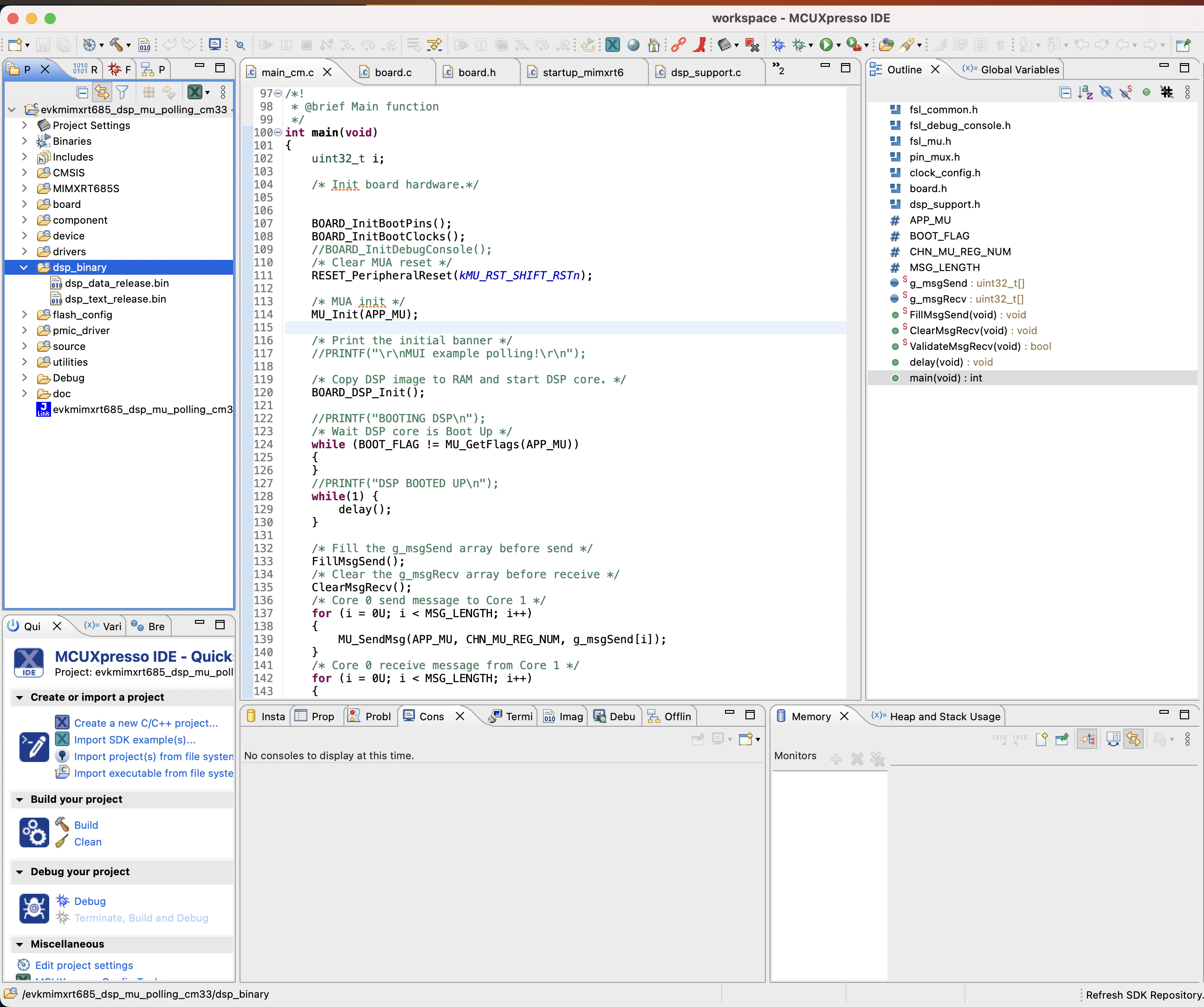
注意
只要使用 Linux 上的 Xtensa 工具链构建了二进制文件,就可以仅通过 MCUXpresso IDE 对板进行烧录并在芯片上运行,该 IDE 可在所有平台(Linux、MacOS、Windows)上使用。
步骤 2. 清理您的工作空间
步骤 3。点击 调试您的项目,这将使板子闪烁您的二进制文件。
连接到您的开发板的UART控制台(默认波特率为115200)上,您应该会看到类似以下的输出:
> screen /dev/tty.usbmodem0007288234991 115200
Executed model
Model executed successfully.
First 20 elements of output 0
0.165528 0.331055 ...